
Struktur dokumen email yang notabene seharusnya memiliki kelengkapan struktur minimal untuk header, pada kenyataannya banyak variasi yang ditemui, terutama email-email yang bersifat spam. Untuk hal ini saya harus melakukan cukup lama waktu penelitian, dan setidaknya program StudiEM ini dapat membaca sebuah mailbox berformat MBOX dengan cukup baik.
Prinsip dasar yang telah dituangkan pada produk program StudiEM ini adalah bagaimana menganalisa kumpulan dokumen email dengan menerapkan beberapa konsep data mining dan statistik, sehingga dapat memunculkan beberapa informasi yang mungkin tidak dapat ditampilkan secara langsung dari kumpulan email tersebut.
Spesifikasi Sistem
Beberapa spesifikasi fungsional yang ditawarkan dari program StudiEM ini antara lain:
- menyediakan informasi sosial (kelompok-kelompok pemakai, disebut user clique, dan juga jaringan sosial dalam kumpulan email),
- menyaring beberapa informasi penting dari masing-masing dokumen email, seperti catatan waktu, informasi URI, Attachment, dan juga nomor telepon,
- menghasilkan struktur tree terhadap email thread,
- pencarian terhadap kumpulan dokumen email,
- visualisasi dalam bentuk grafik statistik terhadap beberapa informasi seperti penyebaran jumlah dan ukuran email, pengelompokan ukuran email, 20 pengirim dan penerima yang sering melakukan transaksi,
- menyediakan informasi mailing list yang diikuti, berdasar header list-id, sekaligus menampilkan tanggal pertama mendapatkan email dari milist tersebut, dan juga tanggal terakhir user mem-post email ke milist, dan juga jumlah email dari masing-masing milist,
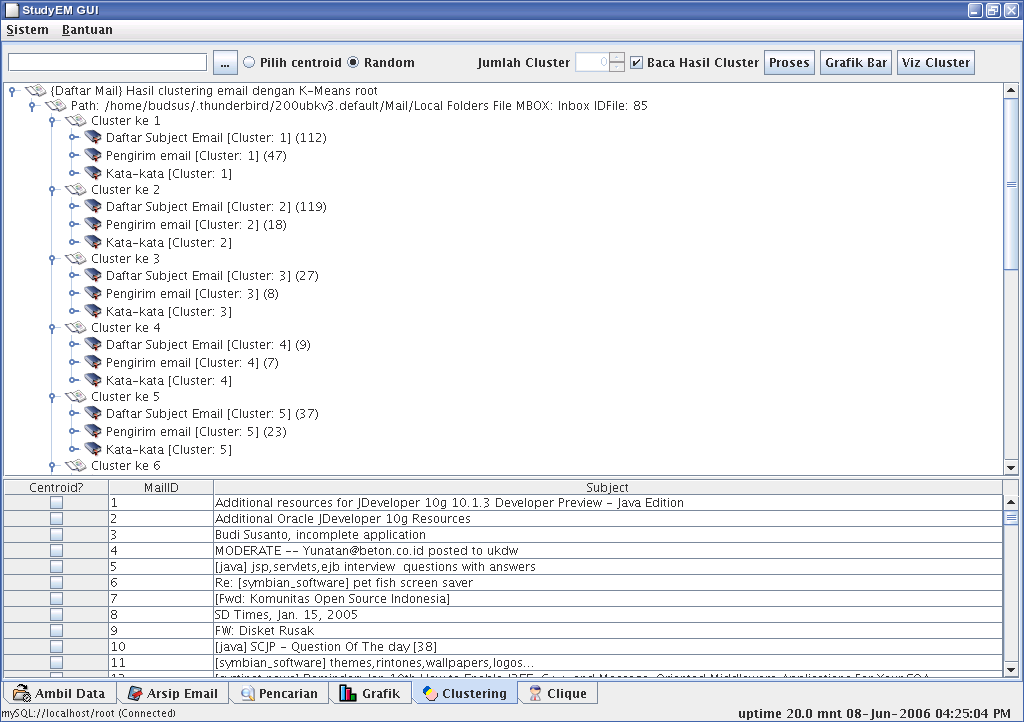
- memberikan fungsi pengelompokan (clustering) dokumen email berdasar bobot kata dari masing-masing dokumen email dengan menggunakan algoritma K-Means (dalam sistem ini disediakan mekanisme penentuan centroid cluster awal baik secara randomize ataupun secara manual user dapat memilih sendiri dokumen email yang akan jadi centroid awalnya),
- dalam proses pembentukan vector kata dan pembobotan, saya tidak menerapkan analisa grammar terhadap tiap-tiap kalimat dalam dokumen email.
Program StudiEM ini menggunakan dua bahasa, yaitu Perl dan Java 1.5. Perl saya pilih karena memberikan kemudahan dalam hal parsing terhadap dokumen email. Sehingga modul Perl yang sudah saya kembangkan antara lain memberikan fungsi:
- proses ekstraksi file MBOX. Hasil dari proses ini adalah akan menghasilkan suatu data yang lebih terstruktur yang tersimpan dalam database MySQL, baik terhadap header email, body email, informasi header attachment (content attactment tidak disimpan), ekstraksi informasi nomor telepon, URI, milist, dan catatan waktu,
- proses parsing terhadap subject dan body email, untuk menghasilkan sebuah bag of words yang masing-masing katanya diberikan suatu nilai bobot TF/IDF, baik kata dalam satu dokumen maupun bobot kata terhadap corpus (seluruh dokumen email),
- menyediakan fungsi transformasi teks, yaitu membuang kata-kata yang bersifat umum (word stop-list), mencari suku kata dari tiap kata (dengan porter stemming, baik untuk bahasa indonesia maupun ingris),
- dari kedua fungsi terakhir tersebut, akan dihasilkan sebuah tabel Term Vector sebagai basis index untuk pencarian dokumen email dan juga untuk analisa cluster,
- menyiapkan beberapa data yang menunjang proses clustering dokumen email, antara lain melakukan features selection dengan cara memilih 30 kata dari masing-masing dokumen email yang memiliki TF/IDF global terbesar.
Untuk menunjang fungsi tersebut, saya menggunakan beberapa modul Perl yang sudah disediakan di search.cpan.org, antara lain:
use Mail::MboxParser;
use Mail::Field;
use MIME::Base64;
use MIME::Entity;
use Mail::Address;
use Text::ExtractWords qw(words_list);
use Lingua::Stem::Snowball;
use Lingua::Identify qw(:language_identification);
use List::Util qw(sum);
use URI::Find;
use URI::Find::Schemeless;
use Mail::Thread;
use Email::Date;
use StemID; # ditulis sendiri
use StopWordEN qw(%StopWordEN); # ditulis sendiri
use StopWordID qw(%StopWordID); # ditulis sendiri
use POSIX;
use DBI;
Hasil semua proses yang dilakukan oleh Perl tersebut akan tersimpan dalam database MySQL, yang selanjutnya akan dibaca oleh program StudiEM yang dikembangkan dengan Java 1.5. Alasan menggunakan Java di sistem ini adalah karena Java multiplatform dan sangat mudah dalam pengembangan sebuah aplikasi GUI. Selain itu Java menyediakan banyak sekali pustaka yang sangat mendukung dalam pengolahan dan menampilkan data dalam bentuk visual. Untuk menampilkan grafik visualisasi data, saya menggunakan pustaka Chart2D dari http://chart2d.sourceforge.net
Blok Kerangka Kerja StudiEM
Blok kerangka kerja dari sistem StudiEM ini dapat dilihat pada gambar 1. Dengan skema tersebut, masing-masing proses sebenarnya dapat dikembangkan dalam modul yang terpisah, dan tentu saja untuk pengembangan ke depan, saya dapat menambahkan beberapa modul lain dalam skema StudiEM agar lebih lengkap.
 Gambar 1.
Gambar 1.Visualisasi Cluster
Ketika akan melakukan visualisasi dari hasil cluster KMean ke suatu bidang grafik 2D, yang berbasis koordinat cartesian X dan Y, ada kendala yang cukup merepotkan, yaitu bagaimana mewakili sekian banyak atribut (kata) dalam sebuah dokumen dengan hanya 2 nilai. Pada akhirnya, saya menemukan sebuah jurnal hasil penelitian yang dilakukan oleh Inderjit S. Dhillon, dan rekan, dalam tulisannya berjudul "Visualizing Class Structure of Multidimensional Data". Dalam tulisannya, Dhillon menawarkan suatu solusi pemetaan dari multidimensi menjadi 2 dimensi dengan cara proyeksi.
Dari fungsi yang diuraikan, pada akhirnya setelah berdiskusi dengan rekan statistik, akhirnya untuk memetakan sebuah data multidimensi menjadi 2 dimensi dengan perhitungan berikut:
Untuk centroid:
 dimana j adalah cluster ke j. mj merupakan vector centroid hasil dari proses clustering KMean. Nilai w merupakan vector konstandengan syarat berikut:
dimana j adalah cluster ke j. mj merupakan vector centroid hasil dari proses clustering KMean. Nilai w merupakan vector konstandengan syarat berikut: Dengan syarat tersebut, agar dapat mencapai nilai maksimal, akhirnya nilai W saya isi dengan:
Dengan syarat tersebut, agar dapat mencapai nilai maksimal, akhirnya nilai W saya isi dengan: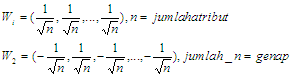
Untuk masing-masing dokumen xi, saya menerapkan sama seperti untuk centroid.
Untuk memvisualisasi hasil koordinat X dan Y tersebut ke Java, saya menggunakan pustaka jChart2D dari http://jchart2d.sourceforge.net.
Visualisasi Clique
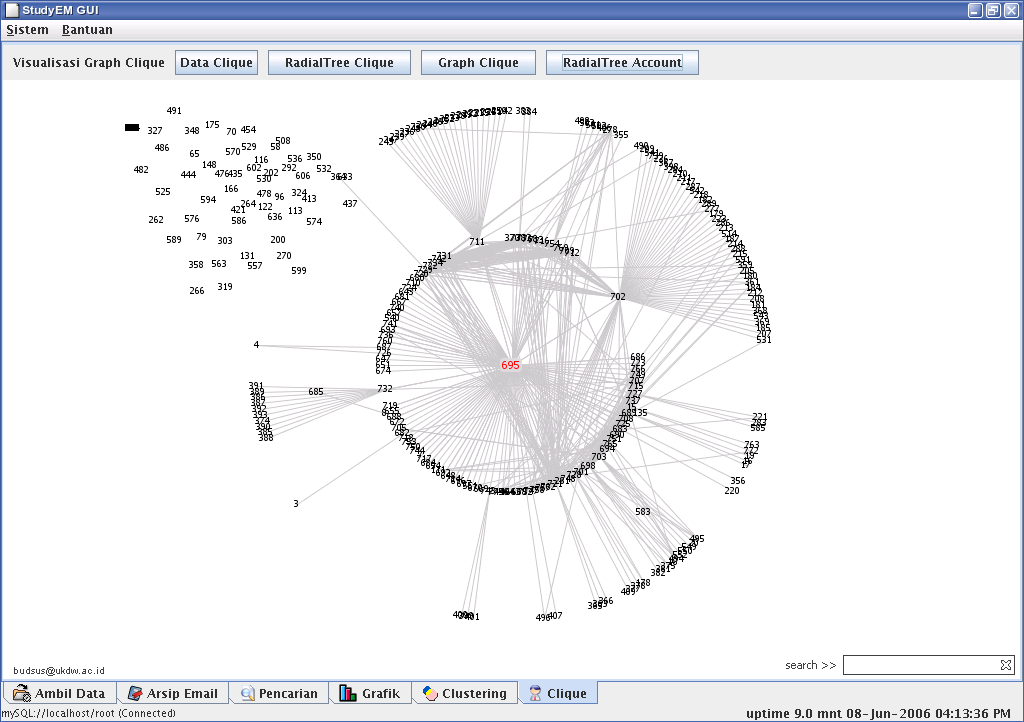
Dengan User Clique kita dapat mengetahui kelompok-kelompok komunikasi yang dapat ditemukan dari kumpulan email seorang user. Pada sistem StudiEM, saya mencoba mengelompokkan berdasar header FROM, TO dan CC. Sedangkan untuk hubungan antar clique, saya menerapkan sebagai berikut: pengirim dari clique A, apakah ada pada clique lain sebagai penerima? jika ya, maka hubungan akan dibentuk.
Pendekatan dalam pembentukan suatu clique, saya dasarkan pada jurnal "Detecting Viral Propagations Using Email Behavior Profiles" yang ditulis oleh Salvatore J. Stolfo, dan rekan-rekan yang juga mengembangkan sebuah sistem Email Mining yang disebut EMT (Email Mining Toolkit).
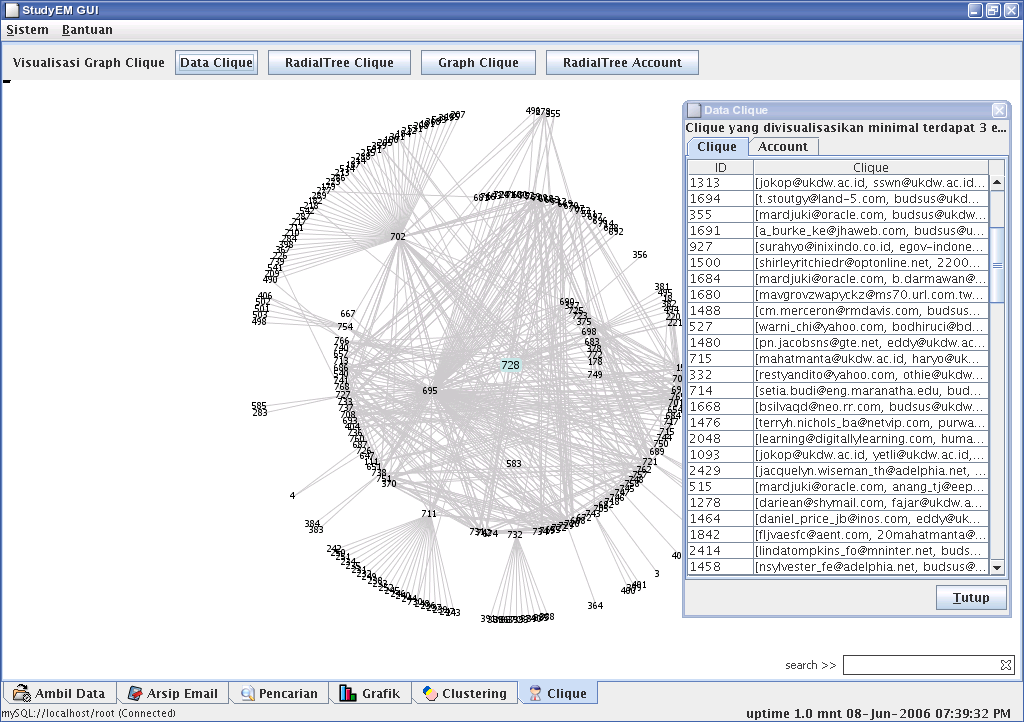
Satu clique, dalam hal ini, saya batasi minimal terdapat 4 pemakai, agar visualisasi dapat lebih baik hasilnya, karena tidak terlalu banyak node yang tergambar. Selain itu dengan minimal 4 pemakai dalam satu clique, sebenarnya sudah dapat dilihat kelompok-kelompok komunikasi yang terbentuk.
Untuk melakukan visualisasi ini, saya menggunakan pustaka prefuse dari http://prefuse.sf.net.
Hasil Program
Masih ada banyak kekurangan dalam sistem StudiEM ini, salah satunya adalah masih perlunya dilakukan optimasi terhadap algoritma agar dapat memproses lebih cepat dengan kebutuhan memori yang lebih sedikit.
Pada dasarnya, clustering dengan KMean cenderung dimungkinkan membentuk sebuah cluster yang memiliki jumlah dokumen lebih banyak daripada cluster yang lainnya. Sehingga, perlu dilakukan optimasi algoritma KMean dan jika dimungkinkan menambahkan beberapa algoritma clustering lainnya sebagai alternatif.
Secara umum sistem StudiEM, dapat digunakan untuk menganalisa sekumpulan dokumen Email dengan memberikan beberapa fungsi yang sekiranya sudah mencukupi untuk kebutuhan sebuah "penambangan emas" dalam tumpukan email.
Snapshoot
Berikut ini beberapa contoh tangkapan tampilan di layar yang dihasilkan oleh sistem Studi EM.
Load Data/Dokumen MBOX dan tampilan Email Thread

Arsip Email hasil ekstraksi
Pencarian Dokumen Email

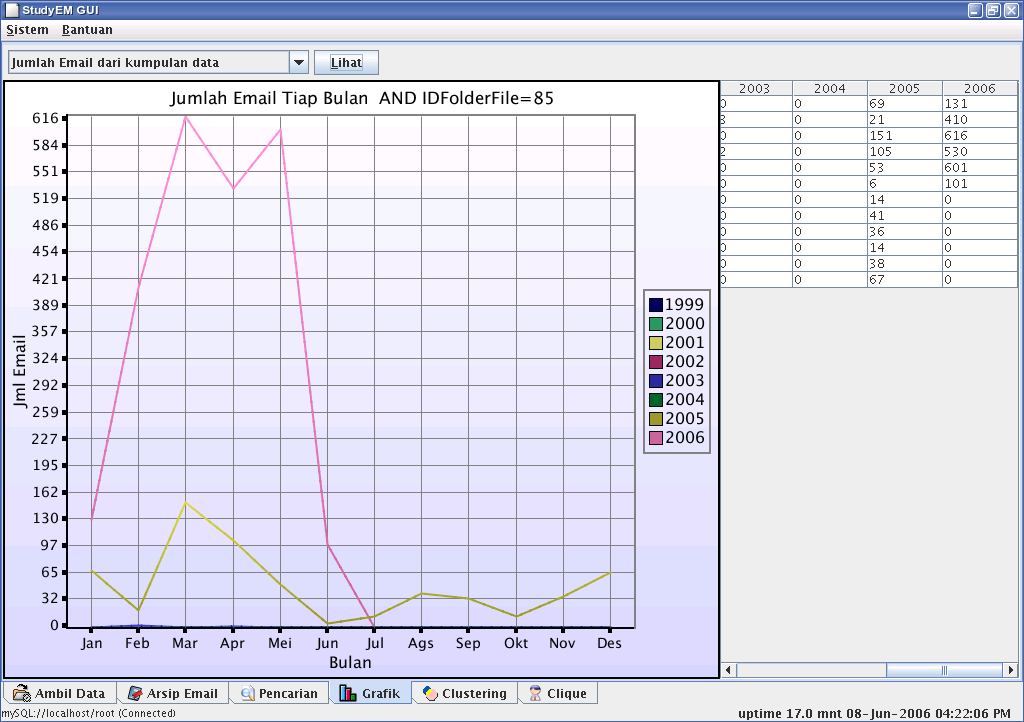
Grafik-grafik
Hasil Clustering KMean

Visualisasi Clique


3 comments:
Waa selamat mas sudah berhasil meraih gelar Magister Teknik.
wah, mantap banget...
baru liat ternyata ada program seperti itu...
kompleks banget...
makasih atas informasi data miningnya...
salam kenal
Ya bagiku sih ini bukan lagi program biasa, dah kompleks banget, banyak bahasa pemrograman, mathematicsnya ada, keren banget deh!
Post a Comment